on
Deep Learning for text made easy with AllenNLP

One of the key principles of a good learning process is to keep learning things just a little above your current understanding. If the subject is too similar to what you already know you end up not making much progress. On the other hand, and if the subject is too hard you’ll stall and make little or no progress.
Deep Learning involves a lot of different topics and things we need to learn, so a good strategy is to start working on something that people already built for us. That’s why frameworks are great. They enable us to not care much about the details of how to build a model so we can focus more on what we want to accomplish (instead of focusing on how to do it).
AllenNLP is a framework that makes the task of building Deep Learning models for Natural Language Processing something really enjoyable. That was a surprise for me, because all my prior experiences with Deep Learning for NLP were some kind of painful.
Working with NLP tasks requires a different type of Neural Network cells, so before getting into how to use the AllenNLP framework let’s take a quick overview of the theory behind theses cells.
🙆 When simple neural networks are not enough
In simple works the task of reading a text consists of building on things we read previously. For example, this sentence would probably make no sense if you didn’t read the sentence before. So the thinking behind the creation of these Neural Network cells was:
“If humans take what they read before in order to understand what comes next, maybe if we use this mechanism in our models they could understand the text better, right?”
🎥 Recurrent Neural Networks
In order to use a network that takes time into account we need a way to represent time. But how do we do that?
One obvious way of dealing with patterns that have a temporal extent is to represent time explicitly by associating the serial order of the pattern with the dimensionality of the pattern vector. The first temporal event is represented by the first element in the pattern vector, the second temporal event is represented by the second position in the pattern vector, and so on. — Jeffrey L. Elman
The thing is that there are several drawbacks to this approach. For example:
[…] the shift register imposes a rigid limit on the duration of patterns (since the input layer must provide for the longest possible pattern), and furthermore, suggests that all input vectors be the same length. These problems are particularly troublesome in domains such as language, where one would like comparable representations for patterns that are of variable length. This is as true of the basic units of speech (phonetic segments) as it is of sentences.
Jeffrey L. Elman talks about other drawbacks in the paper Finding Structure in time. The paper introduces the Elman network, a three-layer network with the addition of a set of “context unities”.
If you’re totally new to neural networks maybe it’s a good idea to read this other article I wrote. But to put simply, a neural network is something that has unities that are activated or not by the inputs.
Elman starts his work based on the approach suggested by Jordan (1986). Jordan introduces recurrent connections.
The recurrent connections allow the network’s hidden units to see its own previous output, so that the subsequent behavior can be shaped by previous responses. These recurrent connections are what give the network memory.
Elman then adds context units. These context units work as a clock to say when we should “let go” the previous inputs. But how? The context units also have a mechanism to adjust the weights, like the other neural network units.
Both the context units and the inputs activate the neural network hidden units. When the neural network “learns” it means that it has a representation of the patterns of all inputs the network processed. The context units remember the previous internal state.
If none of these make much sense, don’t worry. Just think that now we have a neural network cell that takes the previous state into account to produce the next state.
“Now we have a neural network cell that takes the previous state into account to produce the next state.”
📹 When RNNs are not enough: LSTM
As Christopher Ola explains here (this article is awesome if you want to learn more about LSTMs) sometimes we need more context, i.e. sometimes we need to store information that was seen long ago.
Consider trying to predict the last word in the text “I grew up in France… I speak fluent French.” Recent information suggests that the next word is probably the name of a language, but if we want to narrow down which language, we need the context of France, from further back. It’s entirely possible for the gap between the relevant information and the point where it is needed to become very large — Christopher Ola
The LSTM cells solve this problem. They are a special kind of RNN, capable of learning long-term dependencies. We will just use the LSTM cells, not build them, so for our purposes here you can just think of the LSTM cells as cells that have a different architecture and that are capable of learning long-term dependencies.
✨ Building a fancy model for text classification
Ok, enough of theory, let’s go to the fun part and build the model.
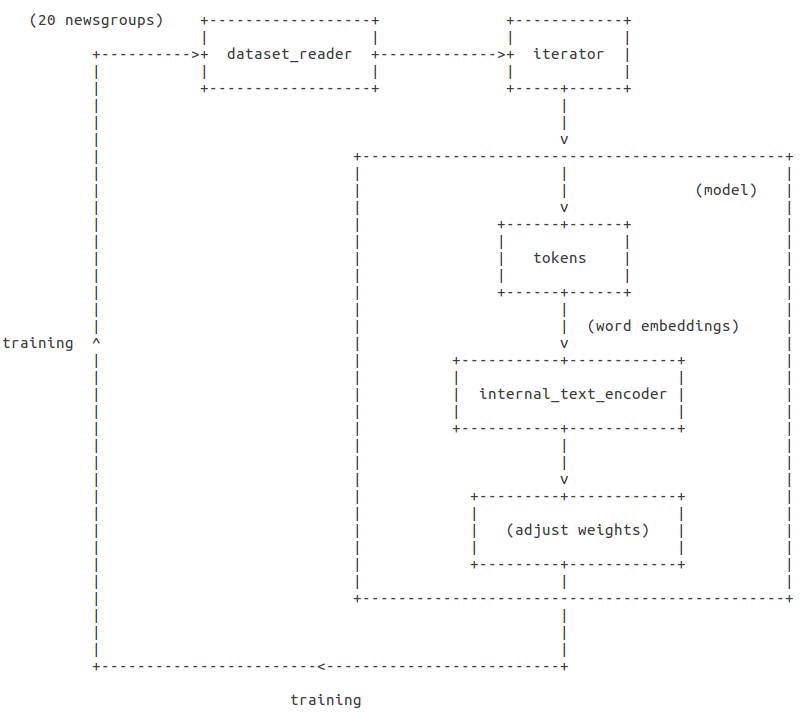 The training process
The training process
The picture above shows us how we’ll set everything. First we get the data, then we encode it to a format that the model will understand (‘tokens’ and ‘internal_text_encoder’) and then we feed the network with this data, compare the labels and adjust the weights. At the end of this process the model is ready to make a prediction.
And now we will finally feel the AllenNLP magic! We will specify everything in the picture above with a simple JSON file.
{
"dataset_reader": {
"type": "20newsgroups"
},
"train_data_path": "train",
"test_data_path": "test",
"evaluate_on_test": true,
"model": {
"type": "20newsgroups_classifier",
"model_text_field_embedder": {
"tokens": {
"type": "embedding",
"pretrained_file": "https://s3-us-west-2.amazonaws.com/allennlp/datasets/glove/glove.6B.100d.txt.gz",
"embedding_dim": 100,
"trainable": false
}
},
"internal_text_encoder": {
"type": "lstm",
"bidirectional": true,
"input_size": 100,
"hidden_size": 100,
"num_layers": 1,
"dropout": 0.2
},
"classifier_feedforward": {
"input_dim": 200,
"num_layers": 2,
"hidden_dims": [200, 100],
"activations": ["relu", "linear"],
"dropout": [0.2, 0.0]
}
},
"iterator": {
"type": "bucket",
"sorting_keys": [["text", "num_tokens"]],
"batch_size": 64
},
"trainer": {
"num_epochs": 40,
"patience": 3,
"cuda_device": 0,
"grad_clipping": 5.0,
"validation_metric": "+accuracy",
"optimizer": {
"type": "adagrad"
}
}
}Let’s take a look on what’s going on there.
1 —Data inputs
To tell AllenNLP the input dataset and how to read from it we set the
'dataset_reader' key in the JSON file.
A
DatasetReaderreads data from some location and constructs aDataset. All parameters necessary to read the data apart from the filepath should be passed to the constructor of theDatasetReader— AllenNLP documentation
Our dataset will be the 20 newgroups and we will define how to read from it later (in a python class). First let’s define the rest of our model.
2 — The model
To specify the model we’ll set the 'model' key. There are three more
parameters inside the 'model' key:
'model_text_field_embedder', 'internal_text_encoder' and
'classifier_feedforward'
Let’s deal with the first one and save the other two for latter.
With the key 'model_text_field_embedder' we tell AllenNLP how the data should
be encoded before passing it to the model. In simple words we want to make our
data more “meaningful”. The idea behind it is this one: what if we could
compare words like we are able to compare numbers?
if 5 - 3 + 2 = 4 why not king - man + woman = queen?
With word embeddings we can do that. This is also good for the model because now we don’t need to use a lot of sparse arrays (arrays with a lot of zeros) as inputs.
Word embedding is the collective name for a set of language modeling and feature learning techniques in natural language processing (NLP) where words or phrases from the vocabulary are mapped to vectors of real numbers. Conceptually it involves a mathematical embedding from a space with one dimension per word to a continuous vector space with much lower dimension. — Wikipedia
In our model we’ll use GloVe: Global Vectors for Word Representation
GloVe is an unsupervised learning algorithm for obtaining vector representations for words. Training is performed on aggregated global word-word co-occurrence statistics from a corpus, and the resulting representations showcase interesting linear substructures of the word vector space. — Glove
If any of this makes sense, just think of Glove as a model where we pass the words and get them encoded into vectors. We’ll set the size of each embedding vector to 100.
Glove takes the words and encode them into vectors
And that’s what the 'model_text_field_embedder' does.
3 — The data iterator
As usual we’ll separate the training data in batches. AllenNLP provides an
iterator called
BucketIterator
that makes the computations (padding) more efficient by padding batches with
respect to the maximum input lengths per batch. To do that it sorts the
instances by the number of tokens in each text. We set these parameters in the
'iterator' key.
4 — The trainer
And the last step is to set the configuration for the training phase. The trainer uses the AdaGrad optimizer for 10 epochs, stopping if validation accuracy has not increased for the last 3 epochs.
To train the model we just need to run:
python run.py our_classifier.json -s /tmp/your_output_dir_here
Another cool thing is that with the framework we can stop and restore the training later. But before that we need to specify the dataset_reader and the model python classes.
👩🏾💻 Writing the AllenNLP Python classes
dataset_reader.py
We’ll use the 20 newsgroups provided by scikit-learn. To reference the DatasetReader in the JSON file we need to register it:
@DatasetReader.register("20newsgroups")
class NewsgroupsDatasetReader(DatasetReader):You’ll implement three methods: read() and text_to_instance().
read()
The read() method gets data from scikit-learn. With AllenNLP you can set the
path for the data files (the path for a JSON file for example), but in our case
we’ll just import the data like a python module. We’ll read every text and every
label from the dataset and wrap it with text_to_instance().
text_to_instance()
This method “*does whatever tokenization or processing is necessary to go from
textual input to an *Instance” (AllenNLP
Documentation).
Which in our case means doing this:
@overrides
def text_to_instance(self, newsgroups_post: str, label: str = None) -> Instance:
tokenized_text = self._tokenizer.tokenize(newsgroups_post)
post_field =
fields = {'post': post_field}
if label is not None:
fields['label'] =
return Instance(fields)We wrap the text from the 20 newsgroups and the label into TextField and
LabelField.
model.py
We will use a bi-directional LSTM network, which is a cell where the first recurrent layer is duplicated. One layer receives the input as is and the other receives a reversed copy of the input sequence. Thus the BLSTM network is designed to capture information of sequential dataset and maintain contextual features from past and future. (Source: Bi-directional LSTM Recurrent Neural Network for Chinese WordSegmentation)
First let’s define the Model class parameters
vocab
Because there are often several different mappings you want to have in your model, the
Vocabularykeeps track of separate namespaces. In this case, we have a “tokens” vocabulary for the text (that’s not shown in the code, but is the default value used behind the scenes), and a “labels” vocabulary for the labels that we’re trying to predict — Using AllenNLP in your Project
model_text_field_embedder
Used to embed the tokens TextField we get as input. Returns Glove vector
representations for words.
internal_text_encoder
The encoder we’ll use to convert the input text to a single vector (RNNs,
remember?). A Seq2VecEncoder is a Module that takes as input a sequence of
vectors and returns a single vector.
num_classes— the number of labels to predict
Now let’s implement the Model class methods
forward()
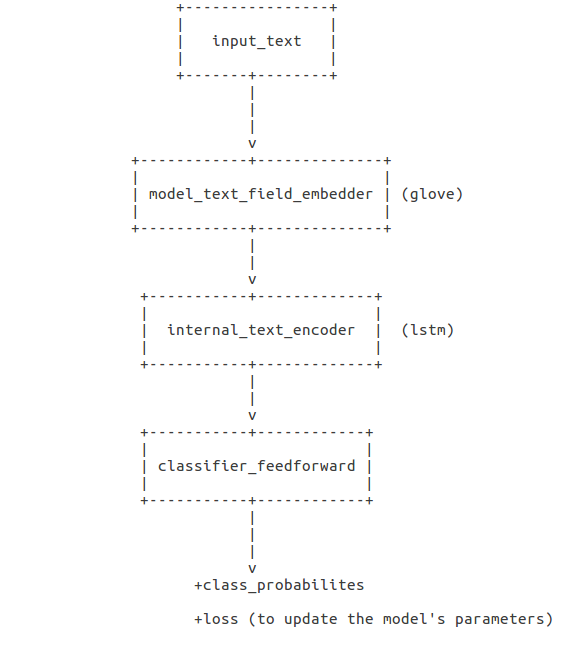 What the forward() method does
What the forward() method does
The first thing that the model does is embed the text, then encode it as a single vector. In order to encode the text we need to get masks representing which elements of the token sequences are merely there for padding.
Then we pass it through a feed-forward network to get class logits. We pass the logits through a softmax to get prediction probabilities. Lastly, if we were given a label, we can compute a loss and evaluate our metrics. — Using AllenNLP in your Project
The forward method basically does the model training task. If you want to understand a little bit more of what’s going on you can go here. Now let’s talk about an important piece of the Model class parameters: classifier_feedforward.
We need
Model.forwardto compute its own loss. The training code will look for thelossvalue in the dictionary returned byforward, and compute the gradients of that loss to update the model’s parameters. — Using AllenNLP in your Project
decode()
decodehas two functions: it takes the output offorwardand does any necessary inference or decoding on it, and it converts integers into strings to make things human-readable (e.g., for the demo). — Using AllenNLP in your
🔃 Running the code
As I said before to train the model though the command line we can use this:
python run.py our_classifier.json -s /tmp/your_output_dir_here
I also created a notebook so we can run the experiment on Google Colaboratory and use the GPU for free, here is the link: https://colab.research.google.com/drive/1q3b5HAkcjYsVd6yhrwnxL2ByqGK08jhQ
You can also check the code on this repository.
We built a simple classification model but the possibilities are endless. The framework is a great tool to create fancy deep learning models to our products. ✨